In this post we'll see how to write event driven microservice using Spring Boot and Kafka. In the example we'll see how to use Kafka as a message broker that enables services to communicate with each other and exchange information.
Message brokers can validate, store, route, and deliver messages to the required destinations. They act as a middleware allowing producers to send messages without having any location information about the consumers of the messages, without knowing whether consumers are currently active or not or what is the count of consumers. This abstraction facilitates decoupling of services within systems and asynchronous communication among the services.
Kafka - Brief introduction
Apache Kafka is an open-source distributed event streaming platform which combines the following three capabilities-
- To publish (write) and subscribe to (read) streams of events
- To store streams of events durably and reliably for as long as you want.
- To process streams of events as they occur or retrospectively.
And all this functionality is provided in a distributed, highly scalable, elastic, fault-tolerant, and secure manner.
Some of the terminology used in Kafka is as given below-
- Events- An event records the fact that "something happened" in your application. When you read or write data to Kafka, you do this in the form of events. The message you write to Kafka may have a key and data which can be a String, a complex object.
- Producers- Those client applications that publish (write) events to Kafka,
- Consumers- Those applications that subscribe to (read and process) these events.
In Kafka, producers and consumers are fully decoupled and agnostic of each other. This clear separation helps Kafka in achieving high scalability. - Topics- Events are organized and durably stored in topics. Topics in Kafka are always multi-producer and
multi-subscriber which means a topic can have zero, one, or many producers that write events to it, as well as zero,
one, or many consumers that subscribe to these events.
Unlike traditional messaging systems, in Kafka, events are not deleted after consumption.
Topics are partitioned, meaning a topic is spread over a number of "buckets" located on different Kafka brokers. When a new event is published to a topic, it is actually appended to one of the topic's partitions. Which partition to send the event is determined by the key passed with the event. Events with the same event key (For example customer ID, account ID ) are written to the same partition, and Kafka guarantees that any consumer of a given topic-partition will always read that partition's events in exactly the same order as they were written.
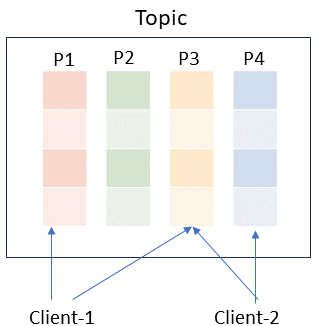
Events with the same key (denoted by their color in the figure) are written to the same partition.
Kafka as message broker
Kafka works well as a replacement for a more traditional message broker. In comparison to most messaging systems Kafka has better throughput, built-in partitioning, replication, and fault-tolerance which makes it a good solution for large scale message processing applications.
Spring Boot Microservice + Kafka Example
In the example we'll create an order-service which acts as a producer of orders and order-consumer-service which gets
that order data and then do further processing of those orders (for example do payment and then change the order status
to processed or rejected).
We'll configure a Kafka topic, order-service will write orders to that topic, order-consumer-service will read orders from the topic.
order-service Microservice
In STS create a new Spring Starter Project and give details as given here.
Name: order-service. Java version used is 17, packaging is Jar and project type is Maven. In the next window select the dependencies as shown in the following image.
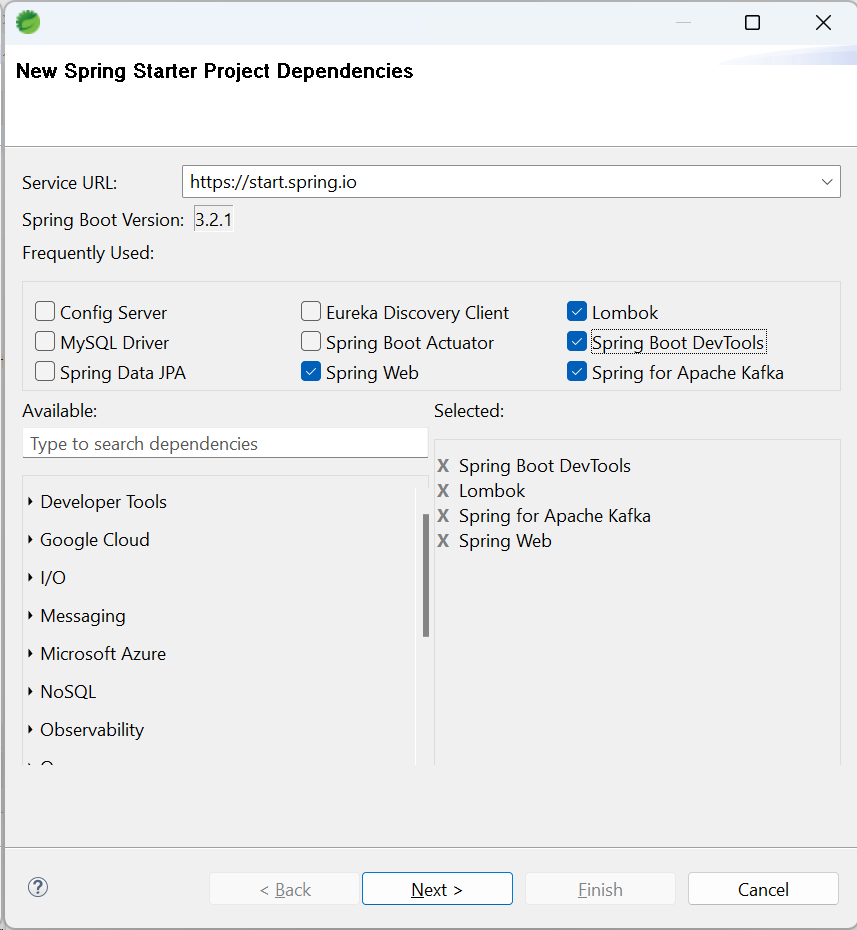
The Spring for Apache Kafka (spring-kafka) project applies core Spring concepts to the development of Kafka-based messaging solutions. It provides a "template" as a high-level abstraction for sending messages. It also provides support for @KafkaListener annotation.
With these dependencies added the created pom.xml should look like this-
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.1</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.netjstech</groupId>
<artifactId>order-service</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>order-service</name>
<description>Order Producer Service
</description>
<properties>
<java.version>17</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
OrderDto class
POJO class used to produce and consume data.
import java.util.List;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Builder
@Data
@NoArgsConstructor
@AllArgsConstructor
public class OrderDto {
private List<String> items;
private double amount;
private String status;
}
Controller Class
Class that will receive request for the designated path and move it forward to Service class.
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.netjstech.orderservice.dto.OrderDto;
import com.netjstech.orderservice.service.OrderService;
@RestController
@RequestMapping("/order")
public class OrderController {
@Autowired
private OrderService orderService;
@PostMapping
public void createOrder(@RequestBody OrderDto order) throws JsonProcessingException {
orderService.sendOrder(order);
}
}
Order Service interface and Impl class
import com.fasterxml.jackson.core.JsonProcessingException;
import com.netjstech.orderservice.dto.OrderDto;
public interface OrderService {
public String sendOrder(OrderDto order) throws JsonProcessingException ;
}
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.netjstech.orderservice.dto.OrderDto;
@Service
public class OrderServiceImpl implements OrderService{
@Autowired
private OrderProducer orderProducer;
public String sendOrder(OrderDto order) throws JsonProcessingException {
return orderProducer.send(order);
}
}
This is the code flow for sending data but we do need to do some configuration for Kafka. Let's start with application.yml file where we'll add the Kafka bootstrap servers and the topic name.
server:
port: 8081
spring:
application:
name: order-service
kafka:
bootstrap-servers: localhost:9092
topic:
name: order-topic
With bootstrap-servers property you can provided a comma separated list of host/port pairs to use for establishing the initial connection to the Kafka cluster. Here we have only a single server.
Producer Configuration
You can provide producer configuration in the application.yml file or create a Java class annotated with @Configuration and provide configuration there. I prefer the latter though with properties file it will look something like this.
spring:
kafka:
producer:
bootstrap-servers: localhost:9092
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
acks: all
topic:
name: order-topic
Here is the OrderProducerConfig.java class that is used in this example to provide producer configuration.
import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.ByteArraySerializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import org.springframework.kafka.config.TopicBuilder;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
@Configuration
public class OrderProducerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.topic.name}")
private String topicName;
@Bean
public Map<String, Object> producerConfig() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class);
props.put(ProducerConfig.LINGER_MS_CONFIG, 2);
props.put(ProducerConfig.ACKS_CONFIG, "all");
props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 60000);
props.put(ProducerConfig.RETRIES_CONFIG, 3);
return props;
}
@Bean
public ProducerFactory<String, Object> producerFactory(){
return new DefaultKafkaProducerFactory<>(producerConfig());
}
@Bean
public KafkaTemplate<String, Object> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
@Bean
public NewTopic topic() {
return TopicBuilder
.name(topicName)
.partitions(1)
.replicas(1)
.build();
}
}
Description for the configuration values provided for the Kafka producers are as given below-
KEY_SERIALIZER_CLASS_CONFIG- Serializer class for key
VALUE_SERIALIZER_CLASS_CONFIG- Serializer class for value
LINGER_MS_CONFIG- Using this configuration you can delay the sending of records rather than sending them immediately. Producer waits for the given duration and group the records arriving during that time to send them together.
ACKS_CONFIG- The number of acknowledgments the producer requires the leader to have received before considering a request complete. acks=all means the leader will wait for the full set of in-sync replicas to acknowledge the record.
REQUEST_TIMEOUT_MS_CONFIG- The configuration controls the maximum amount of time the client will wait for the response of a request.
RETRIES_CONFIG- Setting a value greater than zero will cause the client to resend any record whose send fails.
Using these configurations DefaultKafkaProducerFactory creates a singleton shared Producer instance.
KafkaTemplate is a template for executing high-level operations. When used with a DefaultKafkaProducerFactory,
the template is thread-safe.
A NewTopic instance is also created by passing the topic name which was configured in the application.yml file.
OrderProducer class
For sending message to a specific topic using KafkaTemplate is done in a separate OrderProducer class. ObjectMapper class' writeValueAsBytes() method is used to serialize Order object to byte array.
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.netjstech.orderservice.dto.OrderDto;
import lombok.extern.slf4j.Slf4j;
@Slf4j
@Component
public class OrderProducer {
private final KafkaTemplate<String, Object> kafkaTemplate;
private final NewTopic topicName;
private final ObjectMapper objectMapper;
public OrderProducer(NewTopic topic, KafkaTemplate<String, Object> kafkaTemplate, ObjectMapper objectMapper) {
this.topicName = topic;
this.kafkaTemplate = kafkaTemplate;
this.objectMapper = objectMapper;
}
public String send(OrderDto order) throws JsonProcessingException {
log.info("Sending message='{}' to topic='{}'", order.toString(), topicName);
kafkaTemplate.send(topicName.name(), objectMapper.writeValueAsBytes(order));
return "message sent";
}
}
That concludes the Producer part before moving to the Consumer part let's see how to install Apache Kafka.
Installing Kafka
Simplest way to get Kafka is to run it as a container, here is a docker-compose.yml file that can be used to do that.
version: "3"
services:
kafka:
image: docker.io/bitnami/kafka:3.6
ports:
- "9092:9092"
container_name: broker
volumes:
- "kafka_data:/bitnami"
environment:
# KRaft settings
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_NODE_ID=0
- KAFKA_CFG_PROCESS_ROLES=controller,broker
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka:9093
# Listeners
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=PLAINTEXT
volumes:
kafka_data:
driver: local
Note that Kafka 3.3.1. onward Zookeeper is not required to store metadata about Kafka cluster. Apache Kafka Raft (KRaft) simplifies Kafka's architecture by consolidating responsibility for metadata into Kafka itself, rather than splitting it between two different systems: ZooKeeper and Kafka. That is why Zookeeper instance is not configured in the compose file.
Also note that the port in bootstrap-servers you provided in service (9092) matches the port in your compose file.
To build and start the container use the following command
docker compose up -d
-d switch to run it in detached mode.
After that you can use docker compose stop and docker compose start to stop and start these containers.
Just ensure that all the containers are up by running the following command.
docker ps -a
order-consumer-service Microservice
In STS create a new Spring Starter Project and give details as given here.
Name: order-consumer-service. Java version used is 17, packaging is Jar and project type is Maven. Dependencies are same as given in order-service.
Configuration properties
Since consumer needs to read the data written by producer so topic name for consumer should be same as producer.
application.yml
server:
port: 8082
spring:
application:
name: order-consumer-service
kafka:
bootstrap-servers: localhost:9092
topic:
name: order-topic
OrderDto class
POJO class used to produce and consume data. This class is same as in order-service.
import java.util.List;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Builder
@Data
@NoArgsConstructor
@AllArgsConstructor
public class OrderDto {
private List<String> items;
private double amount;
private String status;
}
Consumer Configuration
A Java configuration class which provides consumer configuration.
import java.util.HashMap;
import java.util.Map;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.ByteArrayDeserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
import org.springframework.kafka.support.serializer.JsonDeserializer;
@Configuration
public class OrderConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.topic.name}")
private String topicName;
@Bean
public Map<String, Object> consumerConfig() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "order");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, ByteArrayDeserializer.class);
return props;
}
@Bean
public ConsumerFactory<String, Object> consumerFactory(){
return new DefaultKafkaConsumerFactory<>(consumerConfig());
}
@Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, Object>> kafkaListenerContainerFactory(){
ConcurrentKafkaListenerContainerFactory<String, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}
Note the use of ConsumerConfig.GROUP_ID_CONFIG in the class which sets the consumer group ID. The Group ID
determines which consumers belong to which group. If there are four consumers with the same Group ID assigned to the
same topic, they will all share the work of reading from the same topic.
You can use a particular Group ID's offset to check whether there's been new data written to the partition. If there's an event with a larger offset, that means there's new data to read. If there are more consumers with the same group ID and same topic then any one of them can read the new data which is the functionality you may want. In our example which passes order, more consumers having the same group ID will work. Any order is read by only a single consumer. But there are scenarios where you may not want that, in that case group IDs for the consumer should not be same.
Using these configurations DefaultKafkaConsumerFactory produces new Consumer instances.
ConcurrentKafkaListenerContainerFactory is a KafkaListenerContainerFactory implementation to build a
ConcurrentMessageListenerContainer. This factory is primarily for building containers for KafkaListener annotated methods
but can also be used to create any container.
OrderConsumerService
Service class that has a method annotated with @KafkaListener which marks a method to be the target of a Kafka message
listener on the specified topics. With @KafkaListener annotation we can specify a topic.
import java.io.IOException;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.netjstech.orderconsumerservice.dto.OrderDto;
import lombok.extern.slf4j.Slf4j;
@Service
@Slf4j
public class OrderConsumerService {
private final ObjectMapper objectMapper;
public OrderConsumerService(ObjectMapper objectMapper) {
this.objectMapper = objectMapper;
}
@KafkaListener(topics = "${spring.kafka.topic.name}")
public void orderConsumer(byte[] message) throws IOException {
OrderDto order = objectMapper.readValue(message, OrderDto.class);
log.info("Order data- " + order.toString());
// Order status can be changed once it fulfills some criteria
order.setStatus("Processed");
log.info("Order data- " + order.toString());
}
}
Testing Kafka and microservices integration
Start both the Services and also ensure Kafka container is up. Using Postman send an order to the order-service listening on port 8081

Once the order is sent to order-service it should be written to the configured topic by Kafka. Consumer reads the Order data from topic then you can further process the order by doing payment and changing the status to processed or rejected based on whether payment was successful or failed and pass that event to another microservice for further processing of order.
In the order-consumer-service you can verify the logs to see that the order is read by the consumer.
[2m2023-12-27T14:06:46.182+05:30 INFO 17940 --- [order-consumer-service] [ntainer#0-0-C-1] c.n.o.service.OrderConsumerService : Order data- OrderDto(items=[RAM, Laptop, Mouse], amount=725.5, status=ordered) [2m2023-12-27T14:06:46.182+05:30 INFO 17940 --- [order-consumer-service] [ntainer#0-0-C-1] c.n.o.service.OrderConsumerService : Order data- OrderDto(items=[RAM, Laptop, Mouse], amount=725.5, status=Processed)
Reference: https://kafka.apache.org/documentation
That's all for this topic Spring Boot Event Driven Microservice With Kafka. If you have any doubt or any suggestions to make please drop a comment. Thanks!
>>>Return to Spring Tutorial Page
Related Topics
You may also like-











